Running GPT-OSS 120B on RTX 3080 Ti 12 GB at home
Want to run a 120B parameter modern LLM at home, for a moderate amount of investment? OpenAI GPT OSS, llama.cpp and a lot of system RAM make it possible.
Preparing your home host hardware
I have an Intel Alder Lake DDR4 system. It has a “gaming” RTX 3080 Ti I bought during a lottery a few years back which has 12 GB VRAM. It also had 32 GB DDR4 RAM (z690 DDR4 motherboard). Then I saw across this on Reddit: “120B runs awesome on just 8GB VRAM!” - https://www.reddit.com/r/LocalLLaMA/comments/1mke7ef/120b_runs_awesome_on_just_8gb_vram/
It outlines how to run many LLM layers in the recently released GPT OSS LLM models on the CPU / system RAM. The key info is the --n-cpu-moe argument in llama.cpp, and a mention of 64 GB system RAM is minimum for being able to load the gpt-oss-120B models.
So I found some DDR4 32 GB 3600 MHz modules and upgraded the system RAM to 128 GB (cost around $320 altogether) which also happens to be the maximum capacity this motherboard supports. NOTE: the current DDR4 prices are about half of what they were when I first built this system.
Installing the software stack (under Linux, using Debian 13 trixie?)
I did a new Debian 13 (trixie) install onto a 2TB NVMe SSD to have plenty of disk space (those LLM models can get BIG). If I did again, would go instead with Ubuntu if only for its better support of the Nvidia drivers and system power-savings settings. Regardless, I was able to get trixie working with Nvidia drivers.
Installing the proprietary Nvidia drivers
Debian 13 comes with the nouveau driver set installed/enabled for Nvidia graphics cards. These do not have CUDA support which is necessary to run the LLM software out there on Nvidia hardware. There are Debian wiki instructions on how to get the Nvidia drivers working on trixie but the following Reddit post seems to be even more up-to-date. I followed it in the end.
Installing the Proprietary NVIDIA drivers on Debian 13 Trixie [reddit]
Long story short, I used the Debian wiki instructions first to install the drivers, and those instructions got it working with an older release of the Nvidia drivers, but when I installed the CUDA toolkit, they got replaced and the system kept instead using the nouveau drivers.
It wasn’t until a couple troubleshooting iterations I got the latest Nvidia driver set installed, and got them to be used by blacklisting the nouveau kernel modules.
sudo nano /etc/modprobe.d/blacklist-nouveau.conf
# add contents
sudo update-initramfs -u
contents of blacklist-nouveau.conf
blacklist nouveau
options nouveau modeset=0
Some friends to make sure the nvidia drivers are being used:
lspci -nnk | grep -A 3 -i "vga"
# Kernel driver in use: nvidia
nvidia-smi
Install CUDA Toolkit
The instructions were for Debian 12 bookworm, but they worked for trixie
wget https://developer.download.nvidia.com/compute/cuda/repos/debian12/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-toolkit-13-0
llama.cpp
llama.cpp does the heavy lifting of running the LLM models. Itt can download published models from HuggingFace which is what we are going to do.
https://github.com/ggml-org/llama.cpp
Build llama.cpp for CUDA
We’ll use its CUDA support to use our RTX 30 graphics card.
https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md
First, clone the git repo, as in the instructions. Also, make sure that the CUDA toolkit binaries are in your shell PATH.
which nvcc # /usr/local/cuda/bin
sudo apt install cmake cmake-doc
sudo apt install ccache
sudo apt install libcurl4-openssl-dev
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="75;86"
#cmake -B build -DGGML_CUDA=ON # this was not autodetecting SM version #
cmake --build build --config Release
It takes a while to build, but when it’s complete, there’ll be fresh llama binaries in your build area.
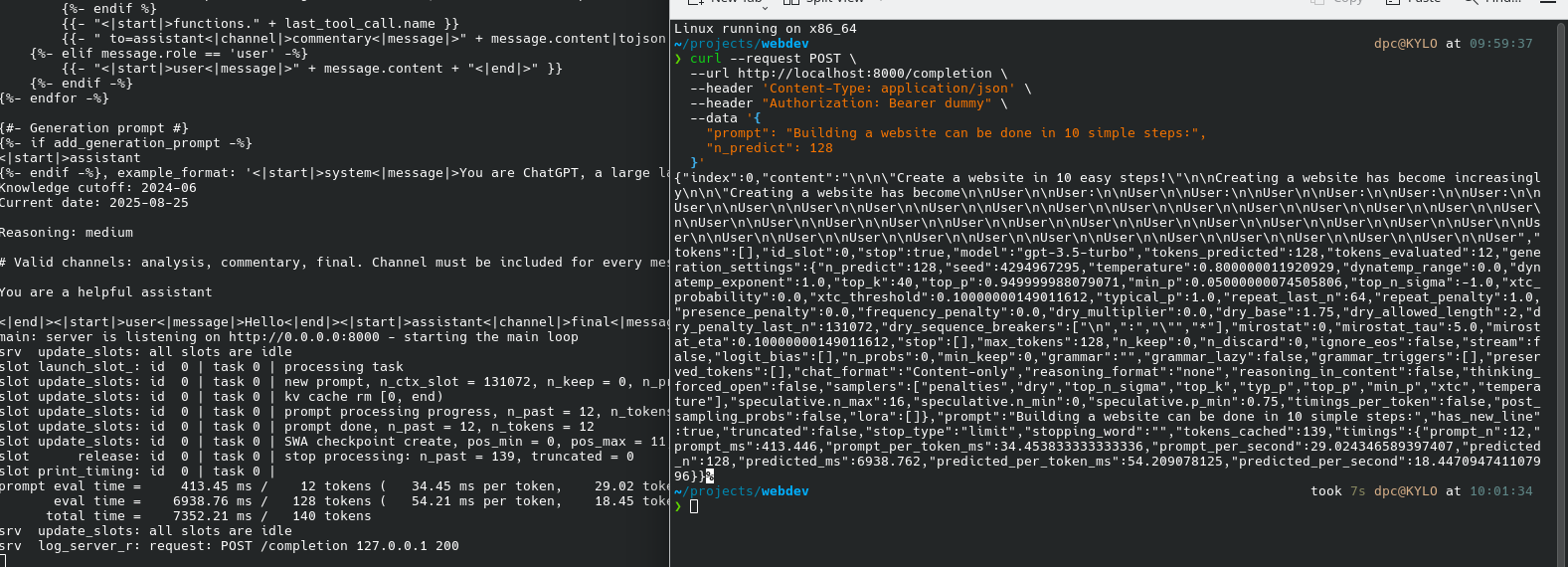
Run llama-server on gpt-oss-120b
./build/bin/llama-server -hf ggml-org/gpt-oss-120b-GGUF \
--n-cpu-moe 36 \
--n-gpu-layers 999 \
-c 0 -fa \
--jinja --reasoning-format none \
--host 0.0.0.0 --port 8000 --api-key "dummy" \
Downloading the 60 GB model files can take a while even at 55 MB/sec.
- The CPU layers consume about 60 GB system RAM (out of 128 GB)
- The GPU layers consume about 6 GB VRAM (out of 12 GB)
I’ve be consistently getting 18-22 tokens/sec output speeds.
See original reddit post referenced above for more on the --n-cpu-moe and --cpu-moe options in llama.cpp along with the gpt-oss models.
Using GPT OSS 120B
I really haven’t been using LLMs personally for much of anything but have of course seen posts out there. (Confession: I have been using small GEMMA 3 models running on a M1 Mac mini to auto-tag karakeep items, but this is not me actively using an LLM for anything)
An actual example.
The time to first token in this setup takes a while, especially for prompts that have larger contexts. Anyway, I have a “Time Temp” python library I’ve using over a decade in some form, and it displays output on LED seven-segment I2C displays, one being the current time: my_7segment_clock.py.
Can my local LLM come up with a python script to do this? Turns out…
Prompt
write a python script script for displaying the current time on an 4 digit 7 segment
LED display connected over an I2C bus to a raspberry pi
API call
curl --request POST \
--url http://localhost:8000/completion \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer dummy" \
--data '{
"prompt": "write a python script script for displaying the current time on an 4 digit 7 segment LED display connected over an I2C bus to a raspberry pi",
"n_predict": 1024}'
Response
the response is JSON formatted, a snippet of which I’ll share here
{"index":0,"content":"?\n\nTo display the current time on a 4-digit 7-segment LED display connected via I2C to a Raspberry Pi, you can use the `smbus2` library for I2C communication and the `datetime` module for obtaining the current time.\n\nHere’s a detailed Python script to accomplish this:\n\n### Hardware Setup\n\n- **4-Digit 7-Segment Display**: Typically ..."}
The whole response was formatted in a Markdown document and contained extensive documentation.
markdown-formatted response
Included in full below. Keep in mind this is the exact output response from the LLM resulting from my prompt above including its repeated-word typo. This output kinda blew my mind when I first saw it!
?
To display the current time on a 4-digit 7-segment LED display connected via I2C to a Raspberry Pi, you can use the smbus2 library for I2C communication and the datetime module for obtaining the current time.
Here’s a detailed Python script to accomplish this:
Hardware Setup
- 4-Digit 7-Segment Display: Typically these displays use a driver like the HT16K33.
- Raspberry Pi: Ensure the I2C interface is enabled.
-
Connections:
- VCC to 3.3V (or 5V depending on your display module)
- GND to GND
- SDA to SDA (GPIO 2)
- SCL to SCL (GPIO 3)
Enable I2C on Raspberry Pi
- Open the terminal.
- Run
sudo raspi-config. - Navigate to “Interfacing Options” -> “I2C” and enable it.
- Reboot your Raspberry Pi.
Install Required Libraries
pip install smbus2
Python Script
import time
import datetime
from smbus2 import SMBus, i2c_msg
# I2C address of the HT16K33 (adjust if different)
HT16K33_ADDRESS = 0x70
# Define segment patterns for digits 0-9
SEGMENT_MAP = {
'0': 0x3F,
'1': 0x06,
'2': 0x5B,
'3': 0x4F,
'4': 0x66,
'5': 0x6D,
'6': 0x7D,
'7': 0x07,
'8': 0x7F,
'9': 0x6F,
'-': 0x40,
' ': 0x00,
':': 0x02 # Colon (optional, depending on display)
}
def init_display(bus):
# Turn on the oscillator
bus.write_byte_data(HT16K33_ADDRESS, 0x21, 0x00)
# Set display to no blink
bus.write_byte_data(HT16K33_ADDRESS, 0x81, 0x00)
# Set brightness (0x0 to 0xF)
bus.write_byte_data(HT16K33_ADDRESS, 0xEF, 0x00)
def set_digit(bus, position, value):
# Write the segment value for a specific digit position
bus.write_byte_data(HT16K33_ADDRESS, position * 2, value)
def display_time(bus, hour, minute):
# Format the time as a string
time_str = f"{hour:02}{minute:02}"
# Split the string into individual digits
digits = [SEGMENT_MAP[d] for d in time_str]
# Set the display digits
for i, digit in enumerate(digits):
set_digit(bus, i, digit)
# Optional: Set the colon (if supported)
# bus.write_byte_data(HT16K33_ADDRESS, 0x04, 0x02) # Turn on colon
def main():
bus = SMBus(1) # Use I2C bus 1
init_display(bus)
try:
while True:
now = datetime.datetime.now()
hour = now.hour % 12 # 12-hour format
if hour == 0:
hour = 12
minute = now.minute
display_time(bus, hour, minute)
time.sleep(1)
except KeyboardInterrupt:
# Clear the display on exit
for i in range(4):
set_digit(bus, i, SEGMENT_MAP[' '])
bus.close()
if __name__ == '__main__':
main()
Explanation
- Segment Map: Defines the patterns for each digit on the 7-segment display.
-
init_display: Initializes the HT16K33 display driver. -
set_digit: Writes the segment data to a specific position. -
display_time: Converts the current time to a format suitable for the display and updates it. -
main: Continuously updates the display with the current time every second.
Additional Notes
- Adjust the I2C address if your display uses a different one.
- The colon display (
SEGMENT_MAP[':']) might need to be handled differently depending on your specific display module. - Ensure your display’s wiring is correct and that the Raspberry Pi’s I2C bus is properly enabled.
This script should provide a basic framework for displaying the current time on
llama-server running